RAG for Web Developers: When to Build It and When Not To
June 11, 2026 0 comments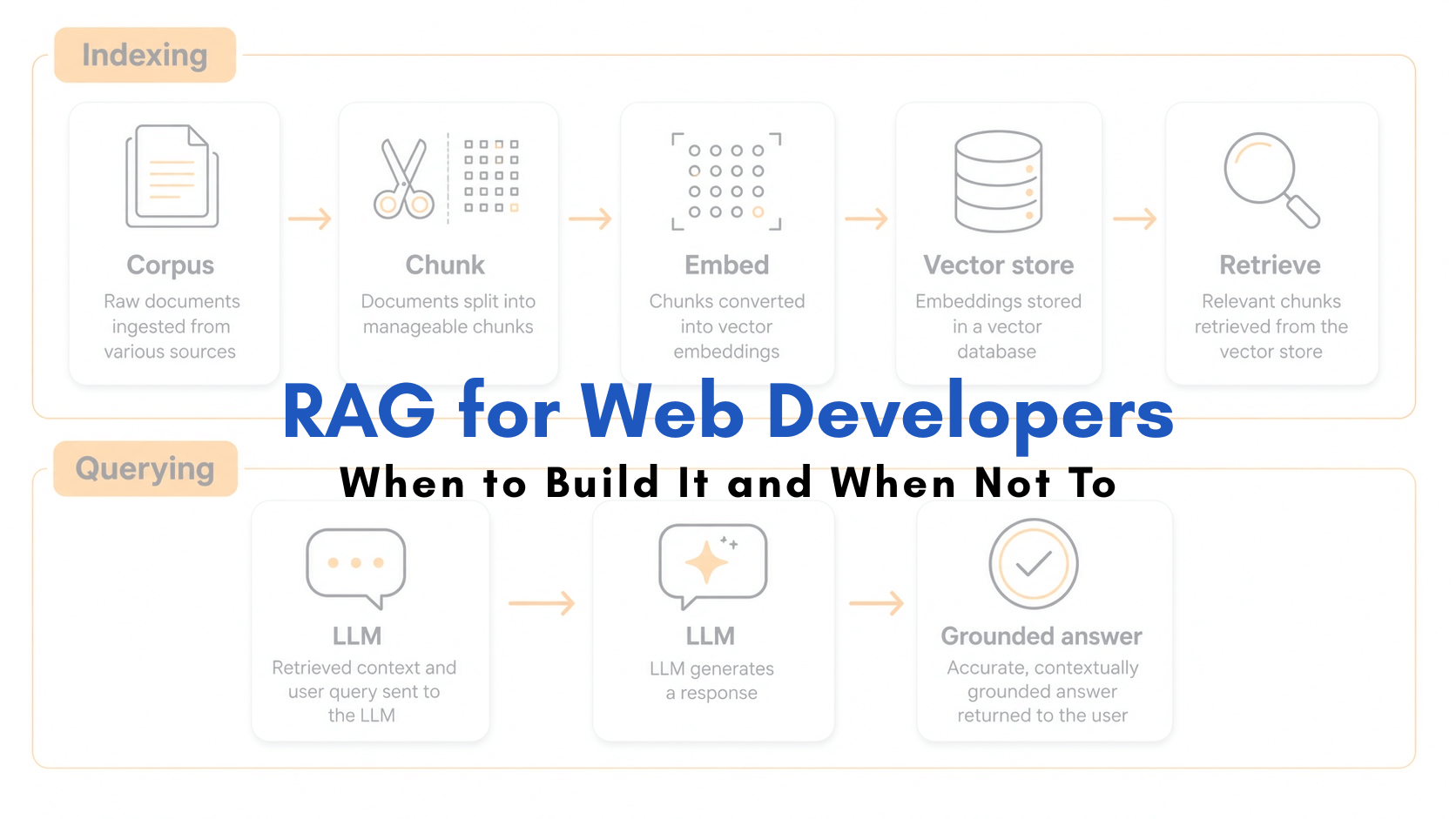
RAG (retrieval-augmented generation) is an architecture, not a model. You chunk your content, embed it into a vector store, retrieve the most relevant chunks at query time, and feed them into an LLM so it answers from your data instead of its training memory. It exists to solve one problem: a knowledge base too large to fit in the model’s context window.
The word “RAG” is doing too much work in client conversations
Most of the confusion comes from collapsing three separate things into one word. A website is a corpus — raw source content. RAG is a pipeline that runs over a corpus, the architecture introduced by Lewis et al. in 2020. And the thing where “ChatGPT already knows about my site” is a third mechanism entirely. If you’re a developer fielding the “should we build a RAG?” question from a client or a founder, the first job is to pull those three apart. They behave differently, you control them differently, and only one of them is something you actually build.
Your website is the food, not the kitchen
A site is input. RAG is the machine that eats it. Saying “our website is already a RAG” is like saying a pantry is already a meal. The pages are content; retrieval-augmented generation is the chunk-embed-retrieve-generate loop that turns content into grounded, cited answers on demand. No loop, no RAG — just files on a server.
RAG isn’t “AI that reads your site.” It’s the plumbing that decides which slice of your content the model sees at the exact moment it answers a question.
Three ways an LLM touches your content — only one is yours
This is the table I wish more people saw before greenlighting a build. The difference between these rows is who owns the pipeline.
| Mechanism | When it happens | Who controls it | Reliable? |
|---|---|---|---|
| Training ingestion | Months before you ask — baked into the weights | The model vendor | No. Stale, lossy, your small site barely registers |
| Live AI search (ChatGPT Search, Perplexity, AI-with-web) | At query time, fetching your live pages | The engine — you only influence it | Partly. This is the AEO game |
| Your own RAG | At query time, over content you chose | You | Yes — current, grounded, cited, debuggable |
The middle row is the one people mistake for RAG. It is retrieval-augmented generation — but it’s the engine’s pipeline, not yours. You shape it through answer engine optimization, clean structure, and machine-readable markup. You don’t own a single line of it. Treating AEO and “build a RAG” as the same project is how budgets get wasted.
The question RAG actually answers
RAG earns its place when your knowledge base is bigger than the context window. That’s the whole reason the architecture exists. You can’t paste a thousand support articles into a prompt, so you retrieve the handful that matter and pass only those. Retrieval is a workaround for a size constraint.
Which means the real design question is never “should we use RAG?” It’s “is my content bigger than the window?” A modern model comfortably holds 200K tokens — roughly a 150-page book. If your entire corpus fits inside that, retrieval is solving a problem you don’t have.
For a small site, context-stuffing wins
If a client wants a chatbot for a fifty-page brochure site, the correct architecture is not RAG — it’s context-stuffing. Put the full content in the system prompt and let the model answer over all of it, every time. Compare the two honestly:
| Context-stuffing | RAG | |
|---|---|---|
| Setup | Paste content into the prompt | Chunking, embeddings, vector DB, retrieval tuning |
| Accuracy | Model sees everything — no retrieval misses | Only as good as what retrieval surfaces |
| Infra to maintain | None | Vector store, re-embedding on content change |
| Right when | Corpus fits the window | Corpus exceeds the window |
Building a vector pipeline over fifty pages is engineering theater. It looks sophisticated and buys you nothing but a database to babysit. The instinct to reach for RAG by default is the same instinct that over-engineers a CMS for a five-page site — resist it the same way you’d resist any premature abstraction, the way you’d approach controlled AI coding rather than letting the tool decide the architecture.
When RAG is genuinely the right call
It flips the moment volume shows up. Build RAG when:
- The corpus is large enough that it can’t fit in one context window — hundreds of documents, long PDFs, sprawling FAQs.
- Content changes often and answers must reflect the current version, not a snapshot frozen in a prompt.
- You need citations back to source — the chunk that produced the answer is the receipt.
- You’re multi-tenant and each client’s data must stay walled off from every other client’s.
- Cost matters at scale — sending only the retrieved slice is cheaper per query than stuffing everything.
That last cluster is where most real product work lives. A managed chat service across many client sites, a support assistant over a deep documentation set, an internal tool over years of project files — those have the corpus that justifies the pipeline. Your own small marketing site almost never does.
What to actually do for a site like yours
For the agency’s own site, the answer is: don’t build a RAG. Point your effort at the live-search loop you don’t own — structure, schema, and clean answer blocks so the engines that fetch your pages can extract them. That’s the same discipline as JavaScript SEO and schema markup, extended to AI readers. Reserve real RAG builds for the client products where content volume is genuine and you can charge for the custom development work.
One honest exception: if your blog grows into hundreds of posts and you want an “ask our blog” assistant with citations, a lightweight RAG over the blog archive — not the whole site — starts to make sense. Even then, go hybrid: full context for the handful of core service pages, retrieval only for the long tail. And whatever you build, keep the codebase legible — RAG glue is exactly the kind of code that rots fast if you don’t write clean code with AI from the start.
You probably don’t need one, and here’s the tell
Most agency and small-business sites fall on the skip side. You can decide in under a minute. Skip RAG if any of these are true:
- Your whole site fits in a single context window: a few dozen pages, a handful of PDFs.
- The content is stable. It doesn’t change weekly, so a snapshot in the prompt won’t go stale fast.
- You don’t need per-answer citations back to a specific source chunk.
- It’s single-tenant: one brand, one body of content, no data-isolation requirement.
- A chatbot here is a nice-to-have, not the product itself.
Macronimous is the textbook skip. Fifty-odd pages, stable content, one brand, no citation requirement. Stuffing the full content into the system prompt is more accurate and zero-maintenance next to a vector pipeline. If your client looks like that, the honest answer is “you don’t need RAG, and here’s the cheaper thing that works.”
Where to start if you actually do
When the corpus is genuinely too big, you have two roads: a framework that hides the plumbing (LlamaIndex, LangChain), or rolling the four steps yourself. For a first real build, roll it. You’ll understand every failure mode, and the whole thing is smaller than it looks.
- Use the store you already run. If you’re on Supabase, pgvector is right there, no new vendor. Pinecone or Qdrant are fine for a dedicated store, but don’t add infrastructure you don’t need on day one.
- Chunk deliberately. Split content into roughly 500 to 800 token pieces with a little overlap, on real boundaries like headings and sections, not blind character counts. Bad chunking is the top reason RAG answers come out vague.
- Embed and store. Run each chunk through an embeddings model (OpenAI text-embedding-3-small is cheap and good enough to start) and store the vector next to the source text and a link back to the page.
- Retrieve, then generate. On a query, embed the question, pull the top few chunks by similarity, and pass only those into the model with an instruction to answer from them and cite the source. That’s the whole loop.
Build it over one real content set end to end before you generalize. The wiring is easy. The hard part is chunking quality and retrieval tuning, and you only learn those by watching real answers and fixing what retrieval missed. Treat version one as a measurement tool, not a finished product.
The short version for your next standup
RAG is a size workaround, not a magic AI feature. Your website is a corpus, not a pipeline. The “LLMs already learned my site” effect is unreliable and not yours to control — AEO is how you influence the part you can. Build RAG when the content is too big for the window and you need it current and cited. For everything smaller, stuff the context and move on. Knowing which problem you have is most of the job, and it’s the same judgment that runs through any sound SEO strategy for 2026.
Figuring Out How AI Engines See Your Site?
We help agencies and businesses get cited by AI search and decide where RAG actually belongs in the build — and where it’s just overhead.
Related Posts
-
 August 1, 2024
August 1, 2024Advanced PHP Coding Techniques: Quick tips for Intermediate Developers
If you're a PHP developer, I am sure you will always look for some Advanced PHP Coding Techniques. I assume You probably already have a grasp of the basics of PHP managing databases and using PHP frameworks. Now it's time to take your skills to the level and learn techniques
PHP Programming, Web Development, web programming0 comments -
 November 20, 2023
November 20, 20237 Reasons for Web Project Failures – Web Development Client Mistakes and How to Avoid Them
7 reasons for web project failures - Case studies and solutions Web development involves parties, including web developers, designers and clients. Sometimes when the web development team does everything, projects can still face challenges originating from the clients side. In this blog post, we will delve into mistakes made by